-
PR-366: A ConvNet for the 2020s자율주행스터디 2022. 1. 24. 13:36

64채널인데 4채널로 만들고 32개로 만들어서 채널을 늘리고, 그룹을 더 늘림
"Use more groups, expand width"
연산량 줄어듦
96개로 키워줌(채널수 너무 적어서)
연산량 5.3G 로 좀 늘어남
--> inverted bottleneck 으로 연산량 줄어들게 함

4배로 키웠다가 줄이는 형태로 inverted
1*1 conv --> FC 층이랑 동일
transformer 안의 MLP 구조는 4배 키웠다가 줄임
똑같이 사용한다(b 그림)
Skip Connection
Resnet Conv
5.3G --> 4.6G 로 줄어듦.
보라색인 Depthwise Conv Layer

보라색의 순서를 위로 올린다

커널사이즈를 7*7 로 바꾸게 됨
이게 제일 퍼포먼스가 나음.

겔루를 쓰자 렐루 대신에

트랜스포머는 mlp 쪽에만 활성함수가 있는데
여기에서도 1*1 conv 하는 쪽 사이에만 겔루를 넣었더니 성능올랐다.

batch norm 없애고 1*1conv 앞쪽에만 넣었더니 성능 오름

그냥 LN 으로 바꾸면 성능 안좋음 그러나 잘 해 보니까 올랐다.

스테이지 2 입장 --> stride2 conv --> 가로세로 사이즈 절반으로 줄임
따로 downsampling layer 가 있다.
2*2 conv with stride2 를 공간 다운샘플링에 넣었더니 발산했고, normalization layer (LN) 을 넣어주니 좋아졌다.
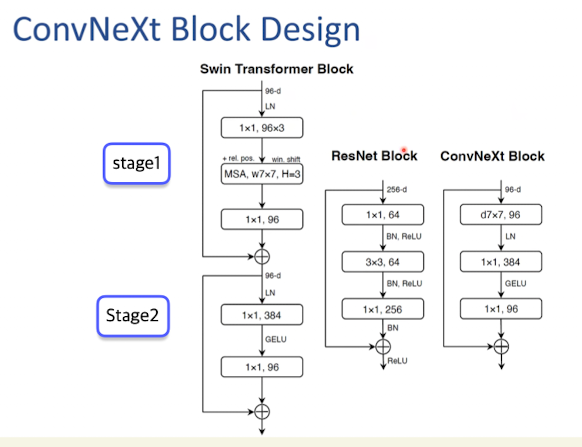
두개의 1*1 layer 사이에만 겔루 하나만 사용(ConvNeXt 을 제안하는 논문)
모든 컨볼루션 한번 하면 --> 배치 norm 하고 이러는게 일반적이었는데... 1*1 layer 전에 BN 하나만 넣음.



큰 디자인 셋에서도 여전히 성능이 좋다
'자율주행스터디' 카테고리의 다른 글
자율주행스터디 0212 (0) 2022.02.12 PR-304: Pretrained Transformers As Universal Computation Engines (0) 2022.01.21 PR-243: Designing Network Design Spaces (0) 2022.01.21 자율주행스터디_2_0121(BiFPN) (0) 2022.01.21 PyTorch "ShortFormer" - RoBERTa w/Chunks(kaggle study__2) (0) 2022.01.21