-
PR-304: Pretrained Transformers As Universal Computation Engines자율주행스터디 2022. 1. 21. 15:46

일부만 이용--> fpt

lstm 보다 좋음?
파라미터는 0.1퍼밖에 되지 않음
자연어 데이터-->pretraining --> vision 으로
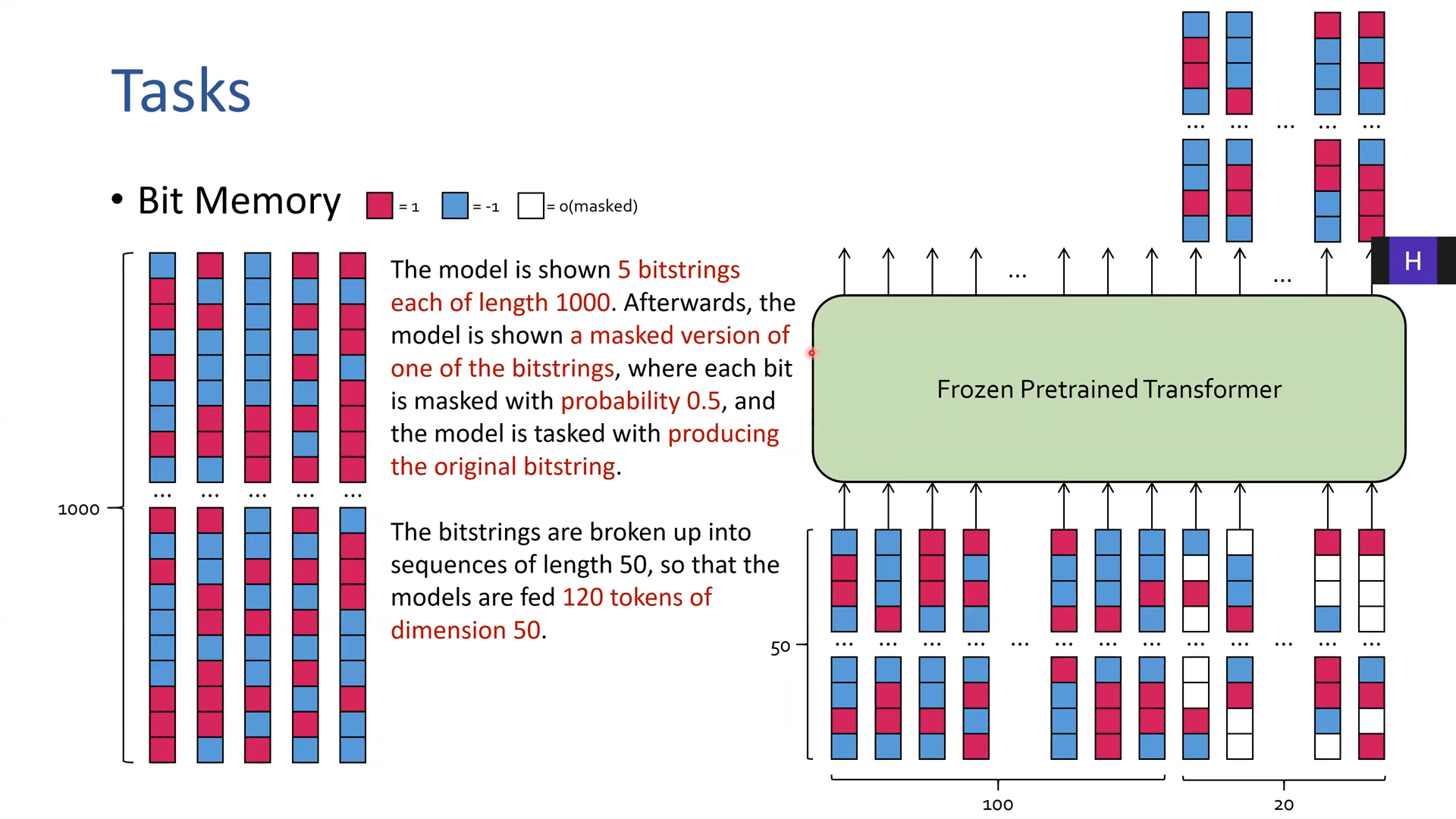
시퀀스 길이 1000개 비트
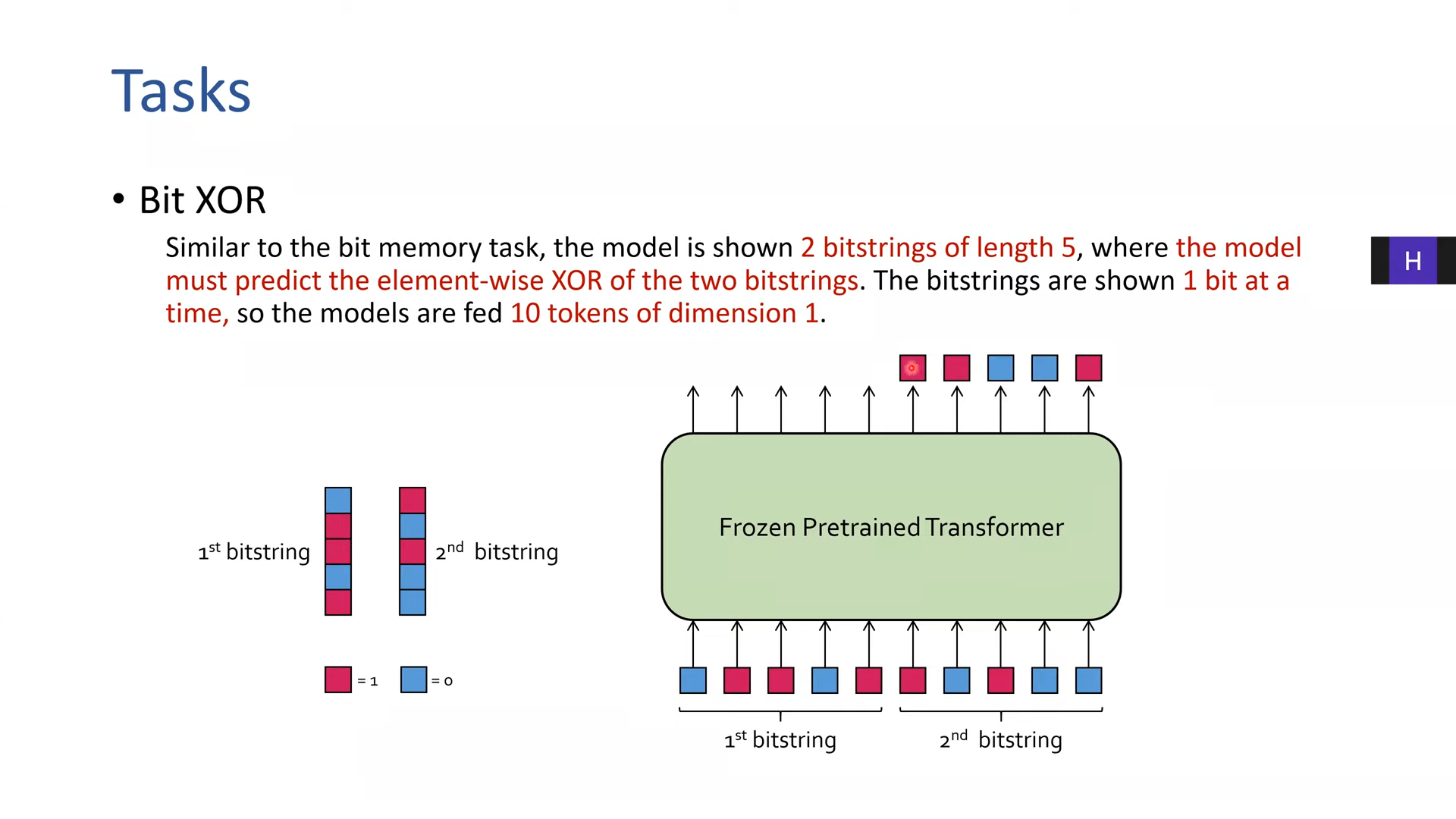

인풋 15
512개의 벡터를 먹임
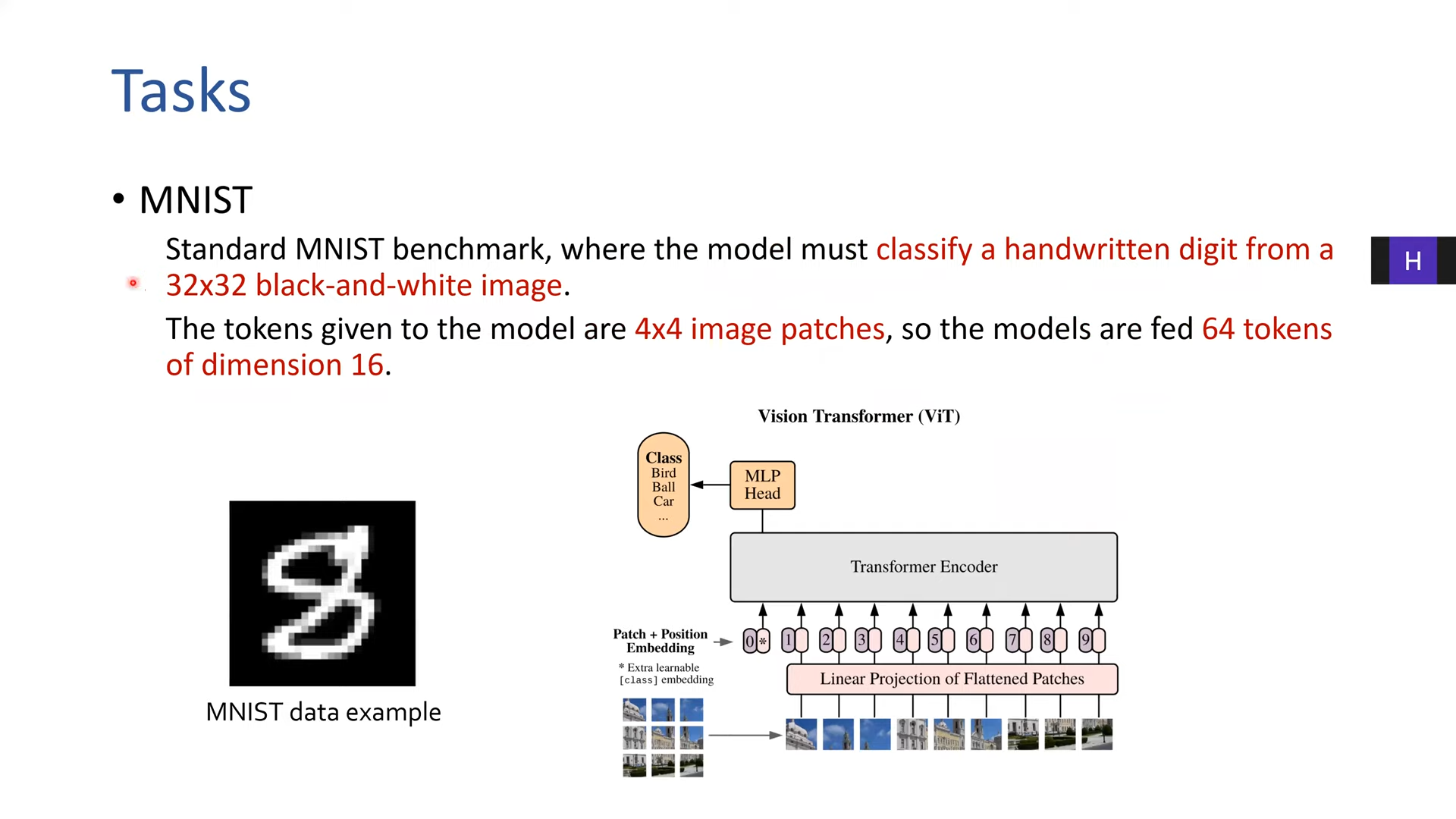
그레이스케일, 4*4로 자르면 8*8 로 64개의 토큰이 생김
4*4 이미지니까 16짜리 디멘션(시퀀스 랭스가 64)

컬러 이미지
Long Range A
gray scale --> 하나하나 bit string 처럼 넣어주는 것
1*1 d이니까 1024개의 토큰 (랭스가 긺)

단백질 접힘 예측

이미지 데이터--> 학습 --> 자연어에 적용? 될 것인가????
transfer 가 잘 될것인지?

feedforward 만 추가했을 때 퍼포먼스 올라감
다 추가하면 오버핏

아웃풋 레이어는 반드시 fine tunning
layernorm 이 젤 높은 성능

자연어 처리 pre training 를 하면
비 자연어 태스크에 연산 이득이 있음
'자율주행스터디' 카테고리의 다른 글
자율주행스터디 0212 (0) 2022.02.12 PR-366: A ConvNet for the 2020s (0) 2022.01.24 PR-243: Designing Network Design Spaces (0) 2022.01.21 자율주행스터디_2_0121(BiFPN) (0) 2022.01.21 PyTorch "ShortFormer" - RoBERTa w/Chunks(kaggle study__2) (0) 2022.01.21