-
joint probability 결합확률 = 조건부확률 *( 예상 확률 )확률 및 통계 2022. 1. 24. 11:58
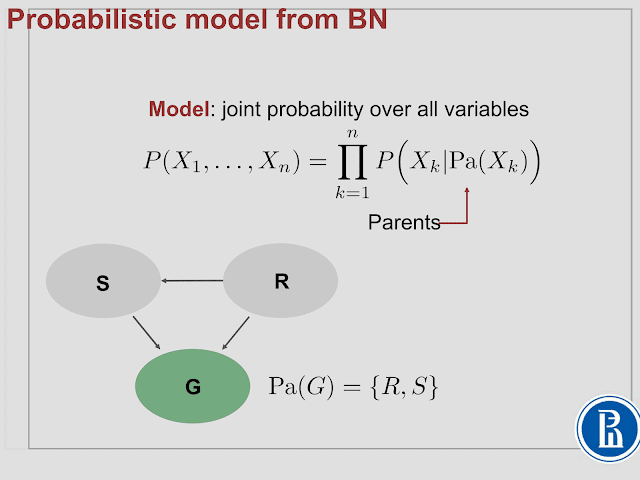
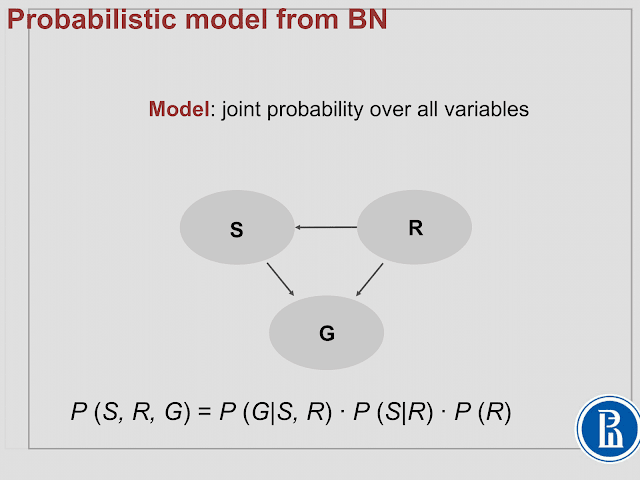
, 로 되어있는게 결합확률
| 로 되어있는게 조건부 확률
P(S|R) P(R) = P(S,R) 이다
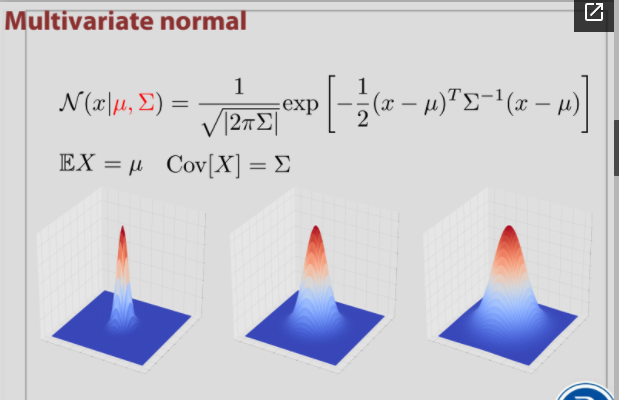
가우시안 분포


p(X|theta) 는 likelihood 함수로, 파라미터 벡터 세타로 본 가능도 함수이다
X는 관측한 데이터로 각각다른 세타의 값들로 관측된 것이다.
likelihood 함수는 세타에 대한 확률분포가 아니라는 점에 명심하라
만약 set X 가 독립적이라면, 가능도함수는 다음과 같이 개별적인, 샘플을 가진 p(x_i|theta)의 가능도함수들의 product(곱) 으로 나타날 수 있다.

p(X|theta)를 직접 최적화하기 보다는 우리는 p(X|theta) 에 로그를 취한것의 맥시멈값을 찾는다.
mu 에 대해서 맥시멈값을 찾는다면, 이것을 mu 에 대해 편미분한뒤 그것이 0 이되는 값을 찾는다. 그렇다면 mu 는 각 샘플을 더한것의 평균이 된다.

만약 샘플 x_i 가 d개의 차원을 가지는 벡터라면 우리는 평균 mu 가 자연수 R의 d 승안에 가우시안 분포로 있음을 알 수 있다.
그렇다면 식은 이렇게 된다(1번째 식)
그다음 로그를 취해준다.

역시, 우리는 mu 가(mean) 샘플을 x_i 가 N 에 대해서 더한 값의 평균임을 알 수 있다.
확률질량함수는 이산값,
확률밀도함수는 연속값에 대한 확률이다.
'확률 및 통계' 카테고리의 다른 글
정규화 ridge(L2), lasso(L1) 와 ElasticNet 의 차이 (0) 2022.01.24 LOSS, likelihood (0) 2022.01.24 Cross Entropy (0) 2022.01.24