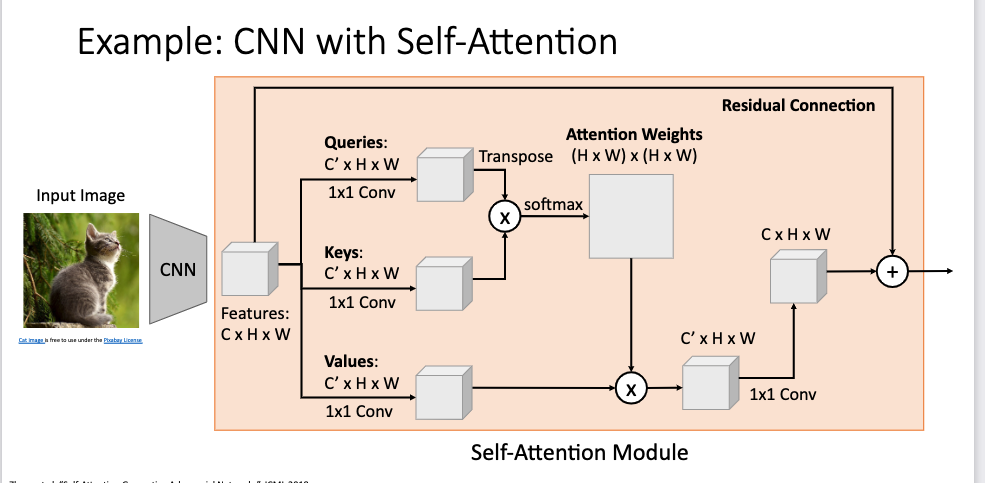
-
자율주행스터디 03 self-attention, transformer카테고리 없음 2022. 2. 5. 11:02

울렁거림이 보입니다. 각 카메라에서 검출된 결과를 Top-view (Bird-eye View) 로 변환 후
그대로 지표면 기준으로 이어 붙이기 때문에 발생하는 결과 입니다
연석체크 가능 벗 떨림 및 휘어져서 주행 불가
(카메라 별 감지 후 융합)
--> 다른 방법 필요

스테레오 카메라 에서도 문제가 있음
(손날을 눈 앞에 두고 왼쪽눈 감으면 왼쪽눈이 보았던 손면이 오른쪽눈에서 안보임)
https://www.youtube.com/watch?v=PkeP6RvHHRE
이미지 후 처리(논문 잘 안나옴) --> resnet
모션 정보 ( 바퀴 휠 )--> 패턴을 미리 알 고 있으면 어떤 부분을 주로 가져갈 수 있게
비젼 + 모션 트래킹 --> 비전을 개선
전방,후방, 좌우 로 4개 fish eye 카메라로 많은 영역 (화각) 커버 (가장자리 왜곡, resolution 이 단점???)
이미지 펴주고 projection --> 가장자리가 쫙 늘어나서 단점
가속기--> 저렴한 하드웨어에서도 텐서로 잘 돌아갈 수 있게 함(라즈베리파이의 가격2배정도)
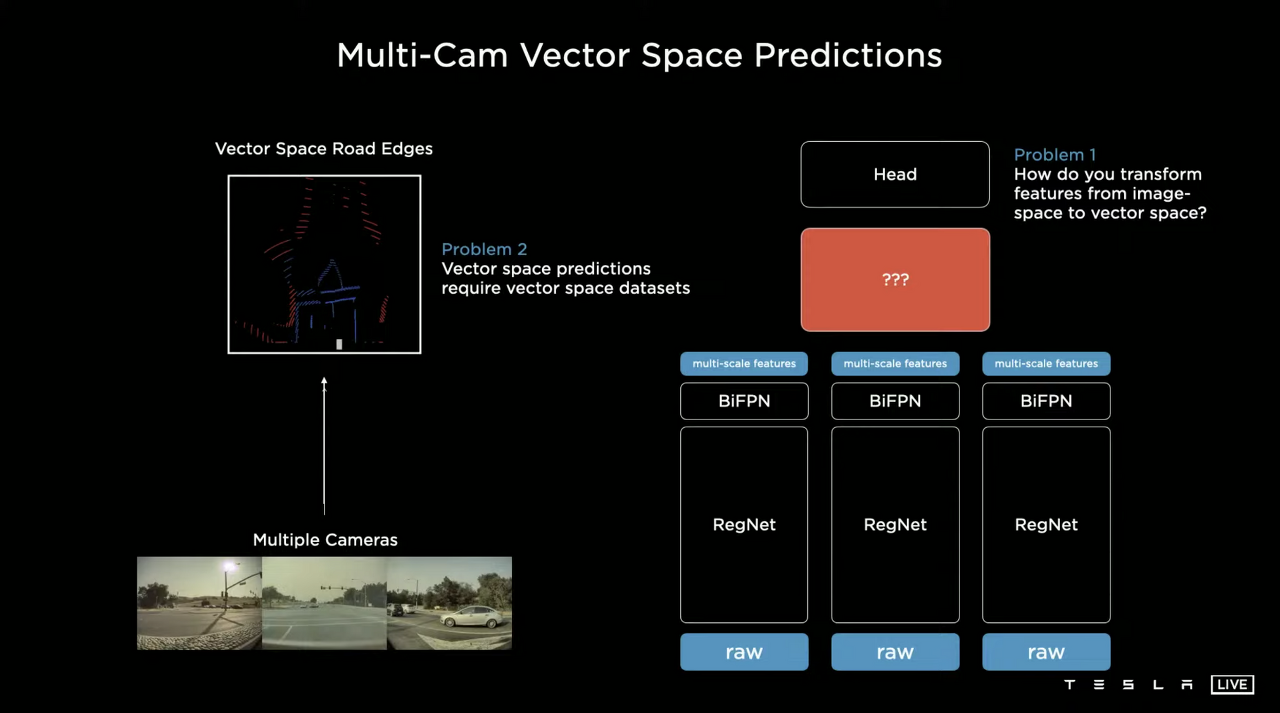

트랜스포머를 이용해 벡터 스페이스로 던질거임
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Chinese (Simplified), French, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture referencing
jalammar.github.io
https://www.youtube.com/watch?v=Yk1tV_cXMMU&list=고려대학교산업경영공학부DSBA 연구실

전체문장 어텐션-->포지션에 대한 타이밍을 주는 것이다
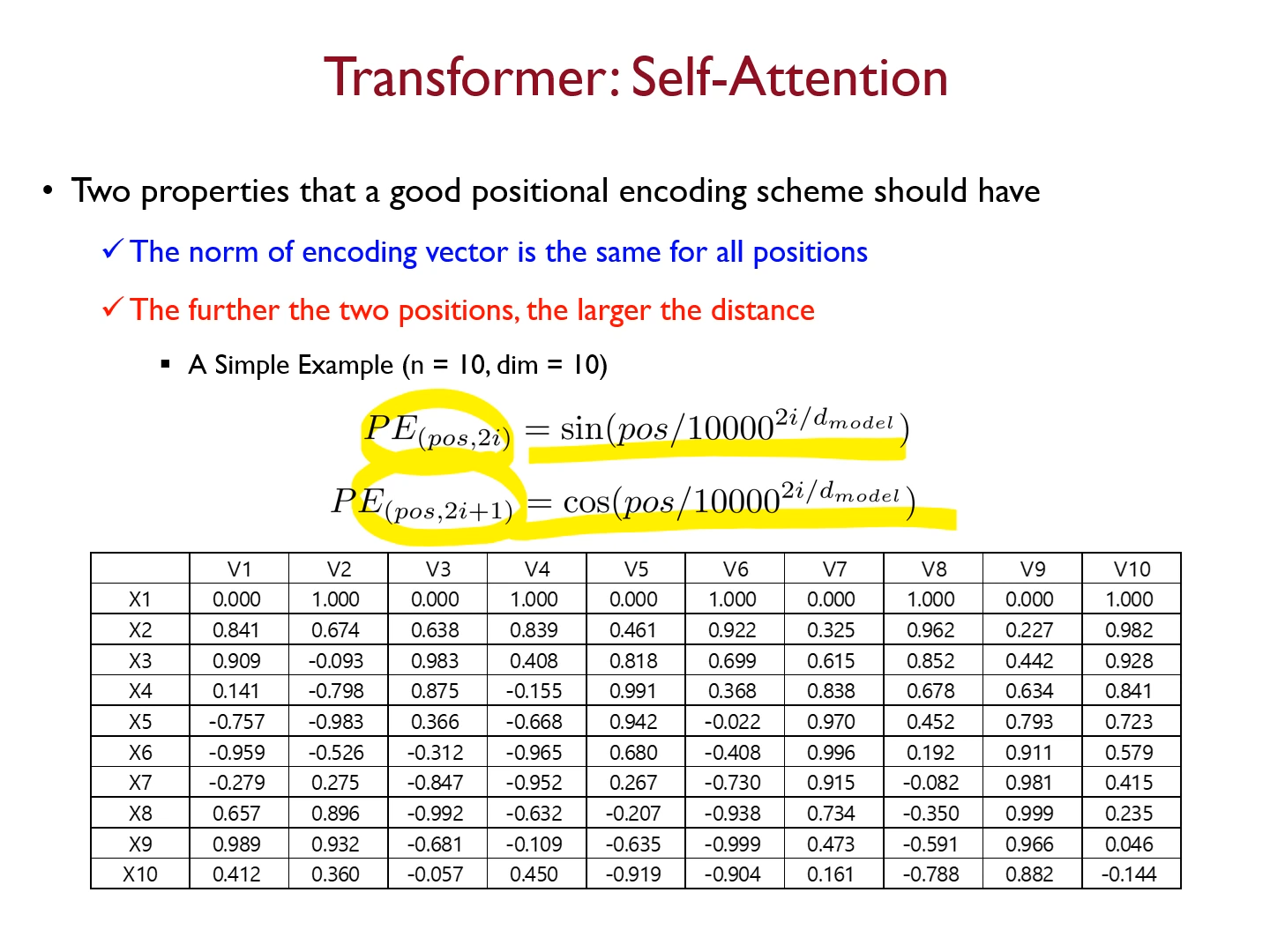
벡터10개==> x1,x2///


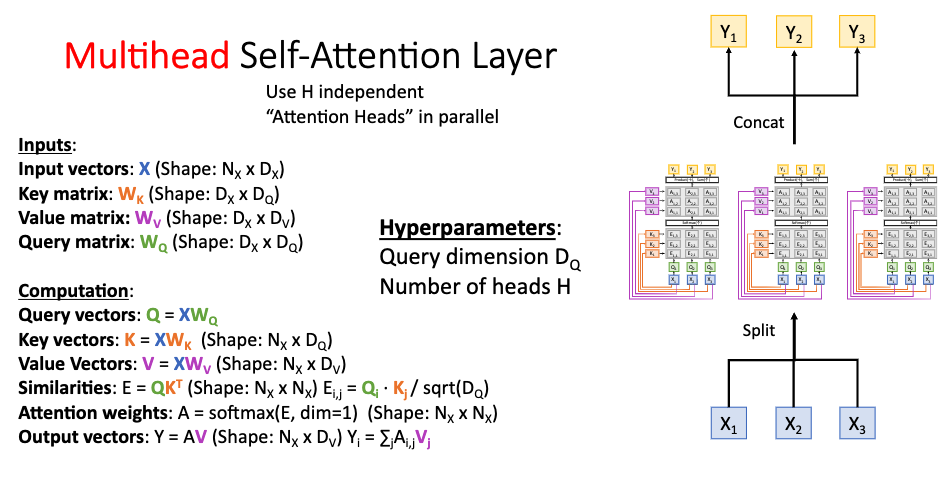
q,k,v 는 인풋 X 에 W_Q,K,V를 곱함으로서 구해진다.

현재관심있는 단어 벡터 = 쿼리 벡터 q
키 = 현재 처리하고 있는 단어가 전체단어에 대해서 어떤상관계수를 가지고 있는지?? scoring을 하기위해 접근하는 구분자 k
최종적인 score 의 값 = 밸류v
멀티헤드 8개 --> 64차원의 q,k,v 벡터 * 8 ---> 512 (인풋 디멘션과 동일한 차원)



k 벡터의 디멘션의 루트--> 루트 64 = 8

가중치 = softmax
모든 값 벨류 sum --> value (self - attention)
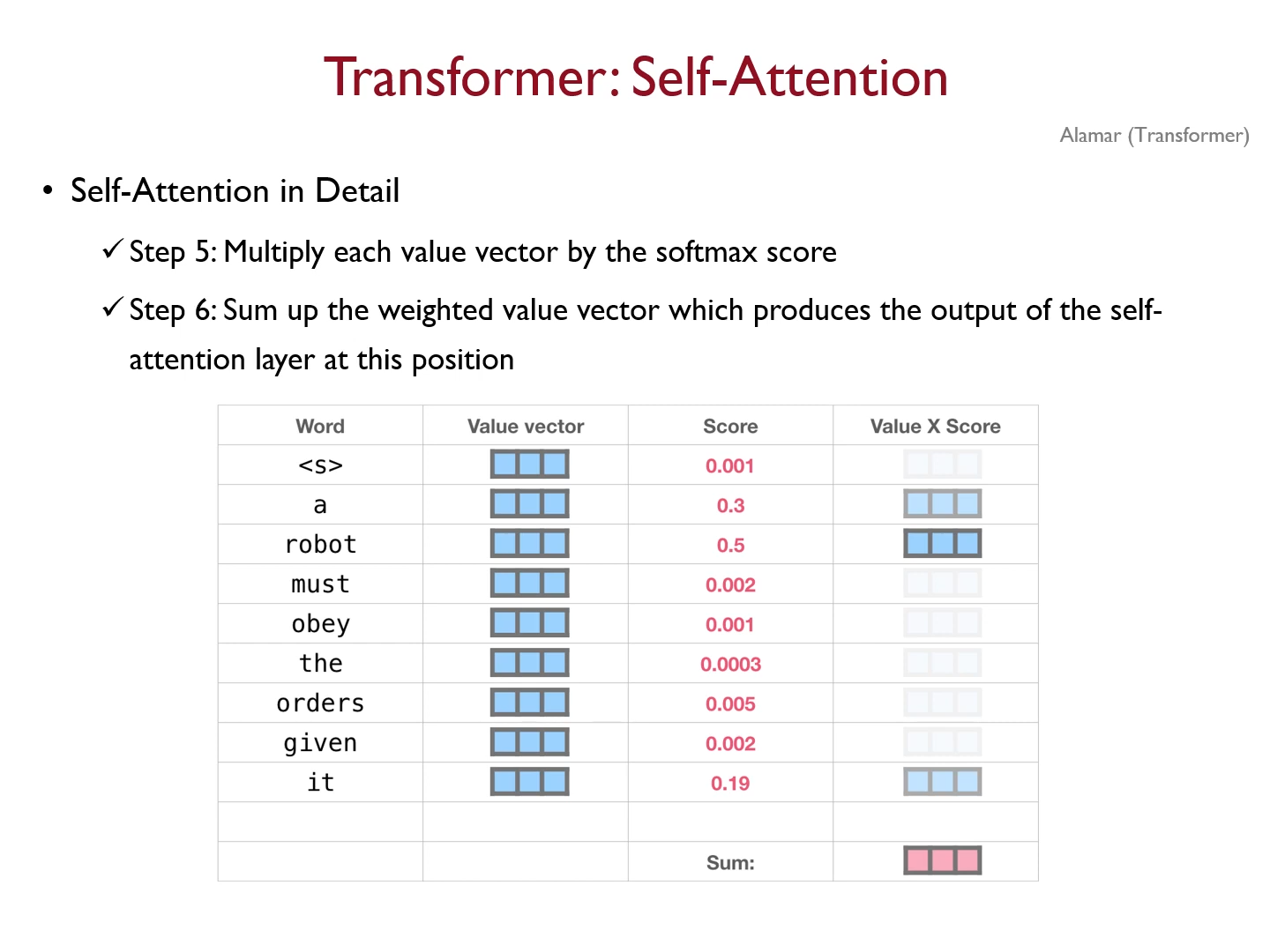

2*3 의 아웃풋 헤드 1개 --> 8개이므로
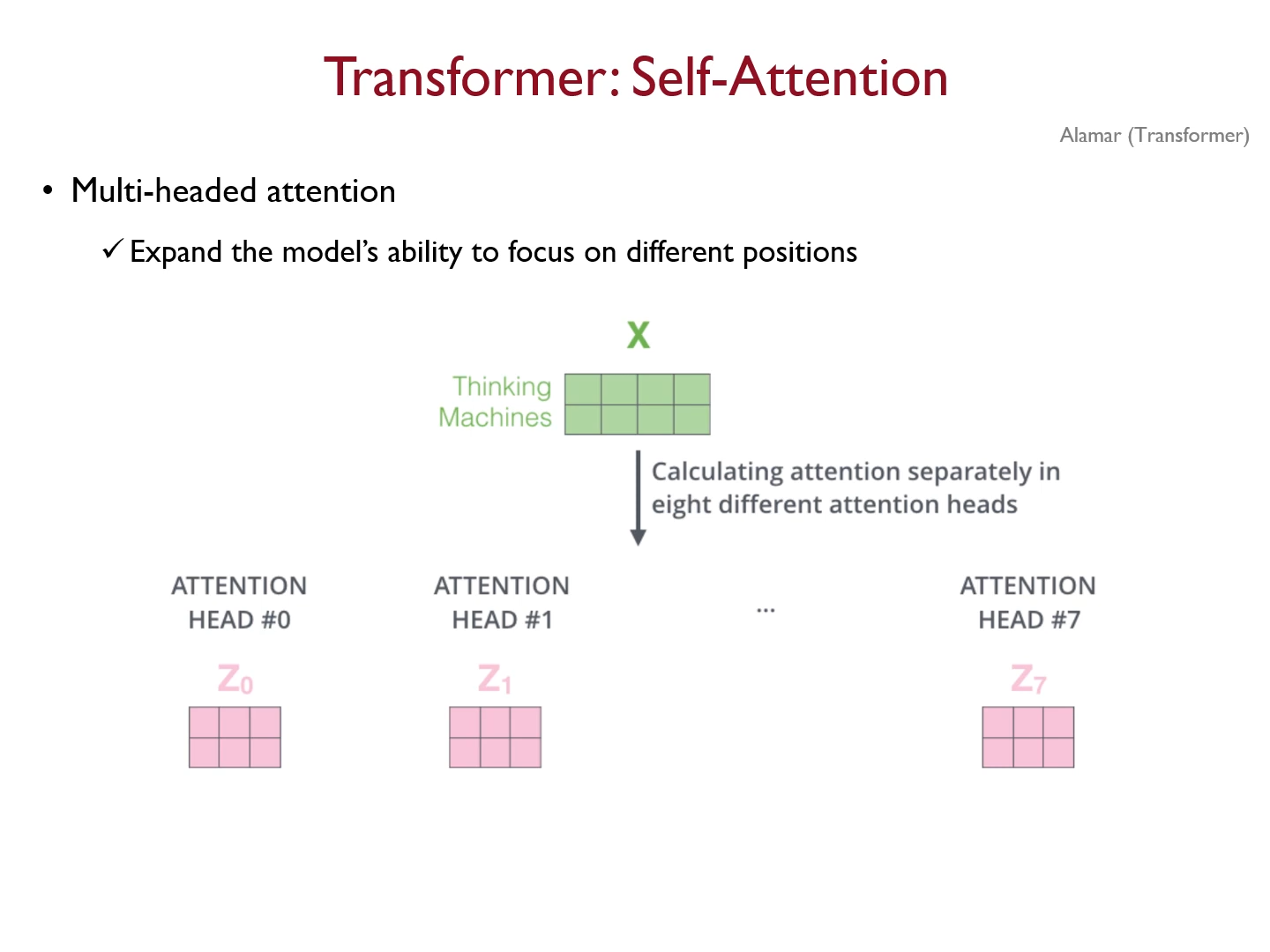
똑같은 두단어에 대한 attention

앙상블 효과 z를 다 concat * W_O(feed forward) 와 연산해서 Z 를 얻음

앙상블 효과 여러개 병렬로 헤드 --> 여러 맥락에서 가능
q,k dot product ==> dimension 이 날아감 !!! dimension 을 키워도 멀티헤드의 효과는 없음
q의 shape (L,D)
k _ tanspose의 shape (D,L) ==>dot product==> (L,L)

feed foward 원리

아래에서 위로, 히든 레이어(relu)==> FC
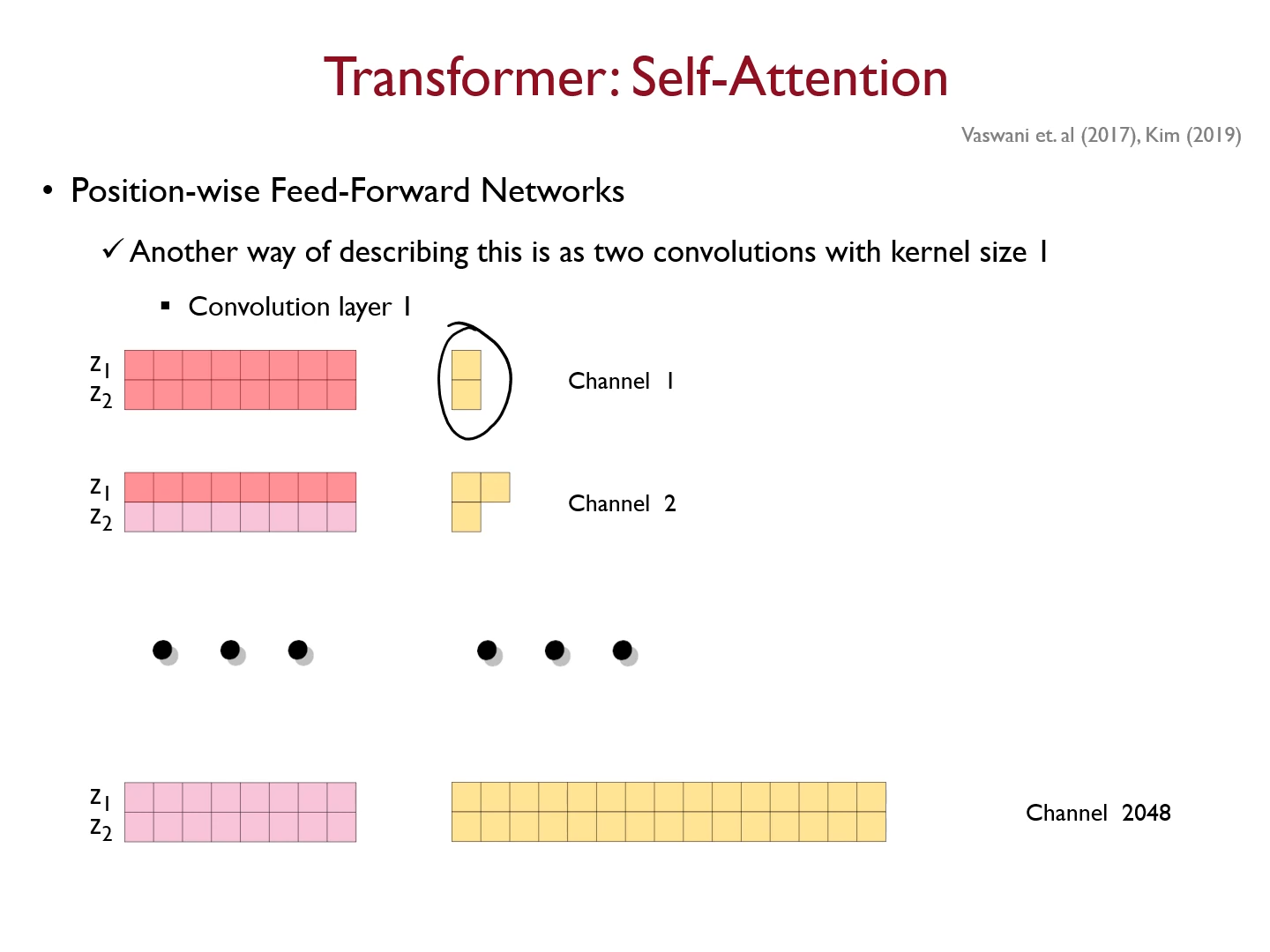
1*1 conv 2 개를 연산함으로서도 feed forward 가 이루어질 수 있다


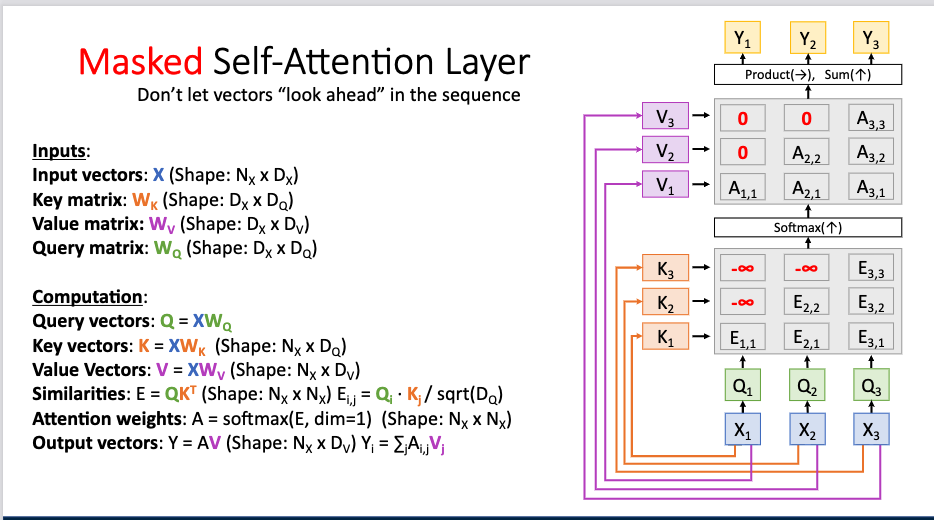
-무한대==> softmax 연산==> 0 이 된다(마스킹)



training ----> 전체데이터다알고있기때문에 중간에서 마스킹함
inference ----> 전혀 주어지지 않아서 하나 넣고 다음단어 뽑아내고 스타트단어다음단어 넣고 다음단어 나오고.. 이런식


자연어쪽에서는 BLEU 를 사용한다.


alignment matrix 뽑음

어텐션 메트릭스

어텐션과 매칭하기 위해서
위--> 아래 sum
왼 --> 오른쪽 : *

쿼리가 없음

linear 로 뽑아냄

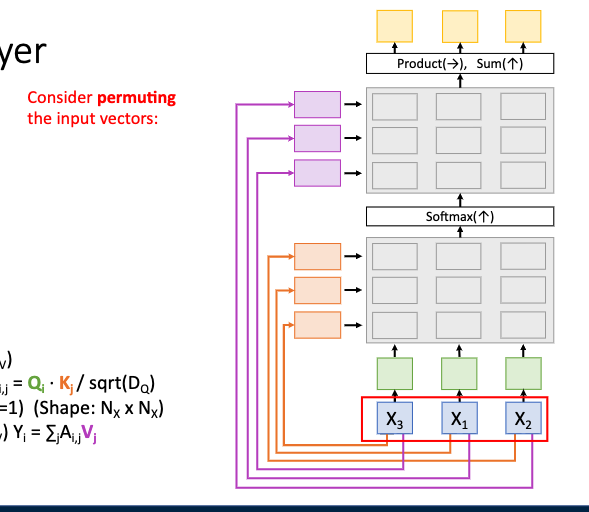

아웃풋은 동일하다
순서를 무시하는 집합의 연산이랑 똑같다
순서가 바뀌면 결과가 안바뀜

그래서 positional encoding 을 해야 한다

픽셀간의 관계
q,k-->attention 을 구하기 위함